
Stable Diffusion (SD) 学习笔记(2024-2025)
从SD小白到实操指导者的学习记录,基于WEBUI,底层逻辑适用于COMFYUI
一、学习感悟与基础建议
- 学习价值:AI是时代机遇,学习具有复利效应,建议每天抽时间学习,从基础(如WEBUI)入手,精通后再进阶COMFYUI(仅报错解决较复杂,核心逻辑一致)。
- 核心原则:模型训练、插件使用、参数调试均需从基础开始,避免跳过关键步骤。
二、SD基础操作:提示词、模型与输出设置
2.1 基础提示词模板(以人物骨骼三视图为例)
- 核心正向提示词:
masterpiece, best quality, 1girl, simple background, (white background:1.5), multiple views, [此处填写自定义特征词], <lora:charturnbetalora:0.6> - Lora权重:0.2-0.6(根据效果调整)
- 输出设置:高清修复,尺寸704*320;预处理器NONE,模型OPENPOSE
- 测试词示例:
masterpiece, best quality, 1girl, blue hair, (orange hat), white jacket, black tank top, pink skirt, upper body, city background - 古风模型ID:3802973867
2.2 通用提示词(正向/负面)
2.2.1 正向通用高画质词
masterpiece, best quality, highres, original, extremely detailed wallpaper, perfect lighting, (extremely detailed CG:1.2), drawing, paintbrush
2.2.2 负面避坑词(广泛适用二次元/写实)
lowres, badhandv4, EasyNegative, EasyNegativeV2, ng_deepnegative_v1_75t, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, NSFW, (worst quality:2), (low quality:2), (normal quality:2), ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), (((extra arms and legs)))
2.3 模型相关(类型、转换、推荐)
2.3.1 模型类型与工具
- 模型辨别工具:https://spell.novelai.dev/
- 模型尺寸要求:WEBUI建议2GB以内,超过需转换(删除EMA权重,避免不兼容)。
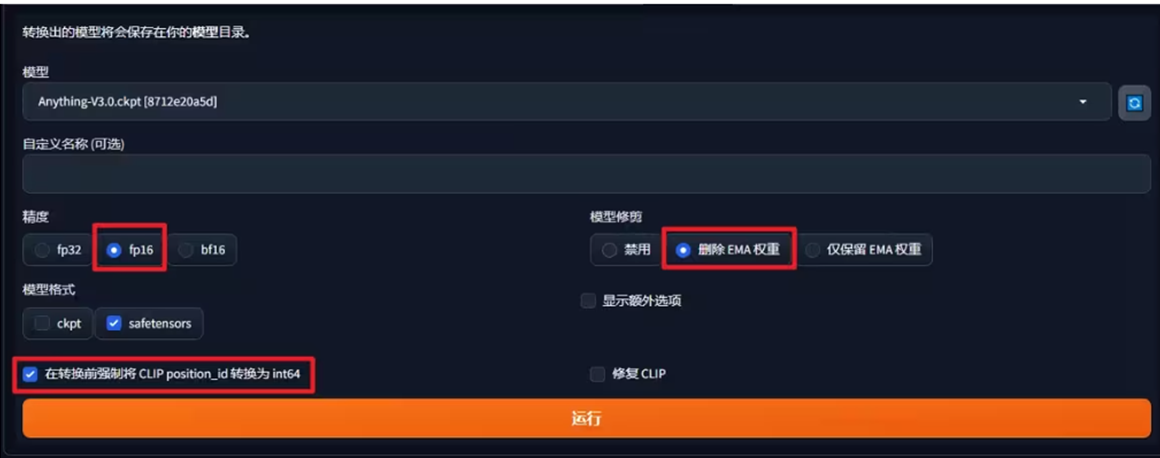
2.3.2 模型转换参数
| 转换选项 | 说明 |
|---|---|
| 精度 | fp32/fp16/bf16(常用fp16,平衡速度与质量) |
| 权重处理 | 删除EMA权重/仅保留EMA权重/禁用 |
| 模型格式 | ckpt/safetensors(推荐safetensors,安全) |
| 额外选项 | 强制CLIP position_id转int64、修复CLIP |
| 转换后路径 | 自动保存至模型目录 |
2.3.3 常用模型推荐
| 风格类型 | 推荐模型列表 |
|---|---|
| 二次元 | Anything-V3.0、Counterfeit、Dreamlike Diffusion、深渊橘、DreamShaper、Meina Mix、Cetus Mix、Pastel Mix、DalcefoPainting |
| 写实系 | Deliberate、Realistic、Lofi |
| 2.5D | NeverEnding Dream、Protogen、国风4 |
| 电商/3D场景 | sdxl_base_1.0、3d类大模型、revAnimated、M-MIX-fifth version |
2.4 快速出图技巧(LCM方法)
- 核心优势:步数少(2-8步)、速度快,适合预览;缺点是画质略有降低。
- 参数设置:
- 采样器:LCM 或 Euler a/Euler
- 勾选「Dynamic Thresholding (CFG SCALE FIX)」
- Mimic CFG SCALE:1
- CFG SCALE SCHEDULER:Half Cosine Up
- Minimum value of the CFG Scale Scheduler:1
- 高清优化:高分迭代步数6,重绘幅度0.5,放大算法R-ESRGAN 4X+ ANIME6B
三、ControlNet全解析(安装、功能与参数)
3.1 安装与文件路径
- 模型路径:ControlNet模型放入
models\\ControlNet - 预处理文件路径:预处理文件(含downloads文件夹)放入
extensions\\sd-webui-controlnet\\annotator(覆盖原有文件)
3.2 核心功能与场景
| ControlNet模型 | 功能用途 | 关键参数/注意事项 |
|---|---|---|
| OPENPOSE | 人物姿态控制 | 无法识别的动作换DEPTH模型;需与人物姿态图匹配 |
| CANNY | 硬边缘控制(如换背景、保留轮廓) | 阈值调高(如233-255)可简化线稿,去除冗余背景;引导终止时机0.3,给提示词更多空间 |
| DEPTH | 深度检测(补全细节、控制层次感) | 适合复杂姿态、场景深度优化 |
| TILE | 增加局部细节、修复分辨率丢失 | 重绘幅度0.6可改风格;Down sampling rate=4时AI自主空间大,适合换衣服 |
| INPAINT | 局部重绘、融图 | 预处理器选inpaint_global_harmonious(全局融合好);蒙版处理选“填充” |
| LINEART/SCRIBBLE | 线稿控制(上色、风格迁移) | 黑色线条上色需改预处理器为INVERT,提示词不含LINEART/monochrome/grayscale |
| BRIGHTNESS/ILLUMINATION | 亮度/照明控制 | 亮度模型:改物体亮度,无需高斯模糊,不与其他模型同用;照明模型:控发光体,需高斯模糊,可与其他模型同用,权重0.4-0.6 |
| INSTANT_ID | 人物一致性控制(仅SDXL模型可用) | 需双重ControlNet:1重参考五官,2重参考人脸位置;CFG与步数需调低 |
| SEG | 语义分割(精准控制画面元素) | 需ADE20K色彩参考表格;预处理器设为“无”,颜色图作前景 |
3.3 ControlNet关键参数调试
3.3.1 控制权重与引导时机
- 控制权重:0.5-1.0(低于0.5控制力度弱,高于1.0易僵硬)
- 引导介入时机:0.05-0.2(介入晚→背景更丰富,结构不变;如scribble模型介入晚可保结构)
- 引导终止时机:0.5-0.9(终止早→形体自由度高;对结构影响小于介入时机)
3.3.2 预处理图分辨率与缩放模式
- 分辨率匹配:勾选“完美像素”,预处理图与生成图分辨率一致(差2倍易锯齿,差3倍易崩)
- 缩放模式:
- 仅调整大小:易变形,不适合比例不同的图
- 裁剪后缩放:易“截肢”,适合比例接近的图
- 缩放后填充空白:适合扩图,重绘幅度需>0.6
四、核心插件与功能应用
4.1 插件安装与路径
- 扩展列表地址:https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui-extensions/master/index.json
- 插件路径:插件文件夹放入
extensions目录,重启WEBUI后在“已安装”中勾选启用。
4.1.1 常用插件功能
| 插件名称 | 功能用途 | 关键参数/用法 |
|---|---|---|
| LLuL | 局部细节重绘 | 精准调整画面局部(如面部、服饰细节) |
| Cutoff | 关键词间隔优化 | 让形容词更精准生效,避免关键词冲突 |
| UltimateSD upscale | 图片高清放大 | 自定义尺寸,重绘0.5左右,放大算法R-ESRGAN 4X+ ANIME6B;分块模式选Chess |
| oldsix | 提示词快速添加 | 左键加正向词,右键加反向词,高效优化提示词 |
| Segment Anything | 精准分割(如换衣服) | 模型选sam_vit_h(2.56GB);检测提示词填“clothes”,蒙版扩展量10-30 |
| fastblend | 视频丝滑度提升 | 输入原视频+AI闪烁视频(尺寸/帧率一致);模式选Fast,滑动窗口=1秒帧率(如60FPS设30) |
| Enhanced-img2img | 批量图生图 | 适合批量处理素材,按文件夹批量生成 |
4.2 实用功能场景
4.2.1 线稿上色
- 预处理模型:LINEART,预处理器设为INVERT(黑色线条)
- 提示词:不含LINEART/monochrome/grayscale,添加色彩描述(如
red hair, blue eyes) - 控制权重:0.7-0.9,引导时机0.1-0.2
4.2.2 换背景(保留主体)
- 前期:用PS/REMOVE BG抠出主体,新建50%灰色图层(混合模式设为“明度”),调色相饱和度(拉满)、可选颜色(匹配明暗部)
- 图生图:发送至蒙版重绘,勾选ControlNet INPAINT,预处理器
inpaint_global_harmonious - 进阶:开启ControlNet LINEART(上传背景图),叠加DEPTH模型提升层次感;重绘幅度1,蒙版处理选“填充”
4.2.3 二维码生成(清晰且美观)
- 控制图尺寸:400400,生成图尺寸768768+(尺寸一致易粗码)
- ControlNet:预处理器“无”,模型QRCODE;控制权重1.1-2(越高二维码越明显)
- 引导时机:0.1-0.3(开始),0.7-1.0(终止);可选ControlNet 2(BRIGHTNESS/ILLUMINATION,权重0.1-0.2)
4.2.4 老照片修复
- 基础修复:开启Tiled diffusion + Tiled vae + ControlNet TILE/BLUR
- 上色:叠加ControlNet RECOLOR模型
- 超分优化:先超分再上色(或反之);后期处理用GFPGAN/CodeFormer(数值0.5),避免面部崩
五、提示词进阶:语法与画风优化
5.1 核心语法(优先级:AND > 逗号 > 权重符号)
| 语法格式 | 作用说明 | 示例 |
|---|---|---|
(关键词:权重) | 提升权重(默认1.1倍,如(white dress:1.5)) | (masterpiece:1.2), best quality |
{关键词:权重} | 轻微提升权重(1.05倍) | {blue eyes:1.05} |
[关键词:权重] | 降低权重(0.9倍) | [blurry:0.8] |
[A:B:步数] | 迭代替换(步数前画A,后画B) | a [fantasy:cyberpunk:16] landscape |
A,B,C AND D,E,F | 多组提示词叠加(两组结果相加) | 1girl, blue hair AND city background, sunset |
| `关键词1 | 关键词2 | 关键词3` |
5.2 画风与画质提示词模板
5.2.1 画风关键词
- 插画风:
illustration, painting, paintbrush - 二次元:
anime, comic, game CG - 写实系:
photorealistic, realistic, photograph - 剪纸风:
jianzhi(需搭配剪纸Lora), paper cut, flat design
5.2.2 画质关键词
- 通用高画质:
best quality, ultra-detailed, masterpiece, hires, 8k - 特定高分辨率:
extremely detailed CG unity 8k wallpaper, unreal engine rendered
5.2.3 提示词结构模板
[画质词] + [画风词] + [主体特征(人物/物体)] + [服饰/细节] + [环境/光照] + [视角/镜头]
示例:masterpiece, ultra-detailed, 8k, anime style, 1girl, blonde long hair, white dress, outdoors, sunset, close-up, wide angle
六、AI动画制作(AnimateDiff、EbSynth、Deforum)
6.1 AnimateDiff(文本/图片转动画)
6.1.1 基础设置
- 模型推荐:V3(效果最优);存放路径参考官方仓库:https://huggingface.co/guoyww/animatediff
- 核心参数:
- 总帧数/帧率:时间长度=总帧数/帧率(如16帧/8FPS=2秒)
- 上下文单批数量:16(模型训练默认值,<8易闪烁)
- 循环模式:N(不循环,适合多镜头);A(循环,适合单场景)
- 插帧:勾选FLIM,插值次数3-5(如16帧插3次→48帧,24FPS=2秒)
6.1.2 进阶技巧(Prompt Travel)
- 功能:按帧数切换提示词,实现场景过渡(如四季变换)
- 示例(总帧数60,帧率8):
masterpiece, best quality, 1girl, upper body, outdoors
0: (spring:1.2), cherry blossoms, pink theme
16: (summer:1.2), sun flowers, green theme
32: (autumn:1.2), maple leaf, orange theme
48: (winter:1.2), snowflakes, white theme
6.2 EbSynth(视频风格迁移/补帧)
6.2.1 核心流程(7步)
- 提取蒙版:项目路径无中文/空格;勾选“透明背景”,蒙版阈值0.01-0.05(分离主体与背景)
- 提取关键帧:最小间隔10,最大300,阈值8.5;多镜头需补关键帧
- 关键帧重绘:图生图选Ebsynth脚本,重绘幅度0.35(无ControlNet)/0.5(有ControlNet);开ADETAILER修脸
- 放大视频:后期处理→批量缩放,尺寸576*1024,算法R-ESRGAN 4X+(写实)/ANIME6B(二次元)
- 生成EBS文件:Stage5生成,存放项目目录
- Ebsynth渲染:导入EBS文件,点Run All(需下载https://ebsynth.com/)
- 合成视频:Stage7生成带/不带音频的MP4
6.3 Deforum(复杂运镜与特效)
6.3.1 Parseq编辑器(参数管理)
- 工具地址:https://sd-parseq.web.app/(需谷歌账号登录)
- 核心功能:
- 提示词管理:按帧数分段设置提示词,Overlap weight设5(过渡帧融合)
- 运镜控制:勾选translation_z/rotation_3d_z等参数,关键帧拖拽调整(如0帧translation_z=1,239帧=4)
- Seed Traveling:种子20→20.1→20.2→21(平滑过渡场景),strength=0.3-0.4
6.3.2 运镜参数含义
| 参数 | 作用说明 | 数值规则 |
|---|---|---|
| 缩放(zoom) | 控制画面放大/缩小 | >1放大,<1缩小 |
| 旋转角度(angle) | 2D旋转 | 正=逆时针,负=顺时针 |
| 3D翻转X(rotation_3d_x) | 上下视角调整 | 正=抬头,负=低头 |
| 3D翻转Y(rotation_3d_y) | 左右视角调整 | 正=向右看,负=向左看 |
| 平移X/Y(translation_x/y) | 2D平移 | X正=右,负=左;Y正=上,负=下 |
七、模型训练(Embedding、LoRA)
7.1 Embedding模型训练(小概念训练,如特定人物)
7.1.1 数据准备
- 图片尺寸:512*512(SD1.5训练默认),用“后期→批量处理”裁剪,勾“自动面部焦点剪裁”(人物)
- 自动打标:BLIP(写实)/Deepbooru(二次元);报错修复:修改
postprocessing_caption.py,将generate_caption改为interrogate
7.1.2 训练参数
- 模型名称:自定义(如“Gaoyunzhen”)
- 初始化文本:默认或填核心特征(如“1girl, long hair”)
- 每个词元向量数:1(默认,复杂概念可增)
- 学习率:0.005(Embedding),0.00001(Hypernetwork)
- 数据集目录:批量裁剪后的图片路径
- 步数:1-2W步(足够拟合)
7.2 LoRA训练(Kohya训练器,推荐)
7.2.1 安装与准备
- 安装教程:https://gf66fxi6ji.feishu.cn/wiki/Q4EYwQl2riWw25kdN3hc5xuEnIe
- 数据准备:
- 图片数量:20-30张(单人),100+张(画风)
- 尺寸:SD1.5→512512,V2→768768,SDXL→1024*1024
- 概念文件夹:命名格式“重复次数_概念”(如“6_Qiuye”,二次元重复5-10,写实10-30)
7.2.2 核心参数设置
| 参数类别 | 选项/建议 | 说明 |
|---|---|---|
| LoRA类型 | Standard/LoCon/LoHa | Standard:通用稳定;LoCon:还原度高(适合人物);LoHa:多概念(适合画风) |
| 训练步数 | 20-30张→1200-1500步 | 最终步数=重复次数×图片数×epoch |
| 学习率 | 1e-4(Standard),8e-5(LoCon) | batch size翻倍→学习率×√2;过高易过拟合,过低易欠拟合 |
| 网络维度(Rank) | 二次元8-32,写实32-64 | 越高细节越丰富,但易过拟合;Alpha=Rank/2(默认) |
| 优化器 | AdamW8bit(通用)/Lion(高batch)/Prodigy | AdamW8bit:稳定;Lion:高batch高效;Prodigy:无参数自动调优 |
| 混合精度 | fp16(推荐) | 平衡速度与显存,BF16需显卡支持 |
7.2.3 训练检验
- Loss值:初期高→逐渐降低→低位震荡(收敛,正常);持续升高/固定→欠拟合/过拟合
- TensorBoard:查看
loss/average(收敛趋势)、lr/textencoder(学习率下降) - 样例测试:每100-200步生成样例,用训练集反推提示词,观察拟合效果
- X/Y/Z图表:WEBUI文生图脚本,对比不同模型/参数效果(如Prompt S/R替换模型后缀)
7.3 数据集清洗(Dataset Tag Editor插件)
- 插件地址:https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
- 清洗步骤:
- 整体审核:删除错词、人物核心特征词(如
white hair,让AI自动学习) - 批量调整:按场景过滤图片(如夜晚图),批量添加标签(如
night) - 单张审核:补全TAG未识别的细节,确保标签简洁无冗余
- 整体审核:删除错词、人物核心特征词(如
八、工具与资源汇总
8.1 模型/插件下载链接
| 资源类型 | 链接地址 |
|---|---|
| ControlNet模型 | https://huggingface.co/ioclab/ioc-controlnet(含亮度/照明模型) |
| AnimateDiff模型 | https://huggingface.co/guoyww/animatediff |
| Kohya训练器 | https://github.com/bmaltais/kohya_ss |
| 抄作业网站 | 欧美风格:https://openart.ai/;亚洲风格:https://arthub.ai/ |
| PIKALABS(AI动画) | https://discord.com/invite/pika |
8.2 常用快捷键与注意事项
- VAE自动匹配:VAE文件名前缀与CHECKPOINT一致
- 插件生效:复制插件到
extensions后,需重启WEBUI并勾选 - 显存优化:Tiled diffusion开启“内存高效注意力”,降低分块尺寸
- 种子固定:
seed: s+f(每帧种子+1,避免闪烁)
九、总结
SD学习核心在于“基础+实操”:先掌握WEBUI的提示词、模型、ControlNet基础,再进阶COMFYUI与模型训练;动画制作需结合AnimateDiff/Ebsynth/Deforum,根据场景选择工具。建议多测试参数(如Lora权重、ControlNet引导时机),利用抄作业网站积累提示词,逐步形成自己的 workflow。
💡
欢迎分享文章,或是与我联系